Quarkus is advertised as a “Kubernetes Native Java stack, …”, so we took it to a test, and checked what benefits we can get, by replacing an existing service from the IoT components of EnMasse, the cloud-native, self-service messaging system.
The context
For quite a while, I wanted to try out Quarkus. I wanted to see what benefits it brings us in the context of EnMasse. The IoT functionality of EnMasse is provided by Eclipse Hono™, which is a micro-service based IoT connectivity platform. Hono is written in Java, makes heavy use of Vert.x, and the application startup and configuration is being orchestrated by Spring Boot.
EnMasse provides the scalable messaging back-end, based on AMQP 1.0. It also takes care of the Eclipse Hono deployment, alongside EnMasse. Wiring up the different services, based on an infrastructure custom resource. In a nutshell, you create a snippet of YAML, and EnMasse takes care and deploys a messaging system for you, with first-class support for IoT.
This system requires a service called the “tenant service”. That service is responsible for looking up an IoT tenant, whenever the system needs to validate that a tenant exists or when its configuration is required. Like all the other services in Hono, this service is implemented using the default stack, based on Java, Vert.x, and Spring Boot. Most of the implementation is based on Vert.x alone, using its reactive and asynchronous programming model. Spring Boot is only used for wiring up the application, using dependency injection and configuration management. So this isn’t a typical Spring Boot application, it is neither using Spring Web or any of the Spring Messaging components. And the reason for choosing Vert.x over Spring in the past was performance. Vert.x provides an excellent performance, which we tested a while back in our IoT scale test with Hono.
The goal
The goal was simple: make it use fewer resources, having the same functionality. We didn’t want to re-implement the whole service from scratch. And while the tenant service is specific to EnMasse, it still uses quite a lot of the base functionality coming from Hono. And we wanted to re-use all of that, as we did with Spring Boot. So this wasn’t one of those nice “greenfield” projects, where you can start from scratch, with a nice and clean “Hello World”. This is code is embedded in two bigger projects, passes system tests, and has a history of its own.
So, change as little as possible and get out as much as we can. What else could it be?! And just to understand from where we started, here is a screenshot of the metrics of the tenant service instance on my test cluster: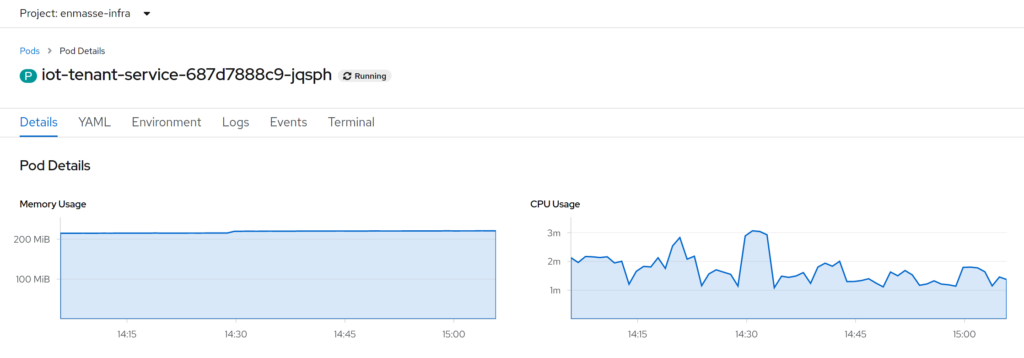
Around 200MiB of RAM, a little bit of CPU, and not much to do. As mentioned before, the tenant service only gets queries to verify the existence of a tenant, and the system will cache this information for a bit.
Step #1 – Migrate to Quarkus
To use Quarkus, we started to tweak our existing project, to adopt the different APIs that Quarkus uses for dependency injection and configuration. And to be fair, that mostly meant saying good-bye to Spring Boot specific APIs, going for something more open. Dependency Injection in Quarkus comes in the form of CDI. And Quarkus’ configuration is based on Eclipse MicroProfile Config. In a way, we didn’t migrate to Quarkus, but away from Spring Boot specific APIs.
First steps
Starting with adding the Quarkus Maven plugin and some basic dependencies to our Maven build, and off we go.
And while replacing dependency inject was a rather smooth process, the configuration part was a bit more tricky. Both Hono and Microprofile Config have a rather opinionated view on the configuration. Which made it problematic to enhance the Hono configuration in the way that Microprofile was happy. So for the first iteration, we ended up wrapping the Hono configuration classes to make them play nice with Microprofile. However, this is something that we intend to improve in Hono in the future.
Packaging the JAR into a container was no different than with the existing version. We only had to adapt the EnMasse operator to provide application arguments in the form Quarkus expected them.
First results
From a user perspective, nothing has changed. The tenant service still works the way it is expected to work and provides all the APIs as it did before. Just running with the Quarkus runtime, and the same JVM as before:
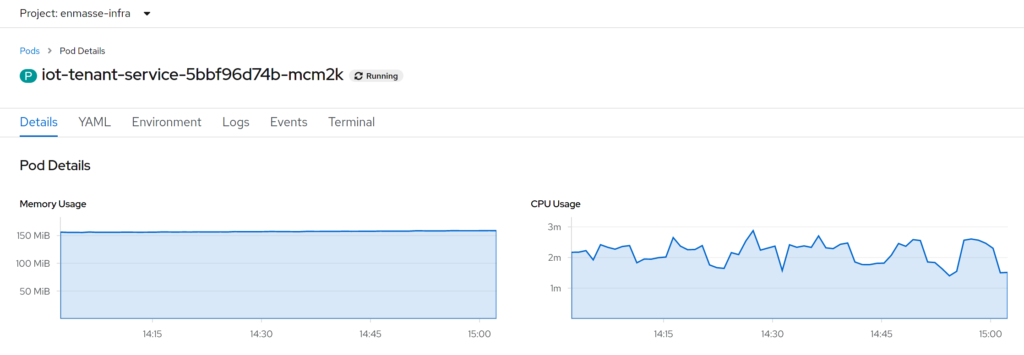
We can directly see a drop of 50MiB from 200MiB to 150MiB of RAM, that isn’t bad. CPU isn’t really different, though. There also is a slight improvement of the startup time, from ~2.5 seconds down to ~2 seconds. But that isn’t a real game-changer, I would say. Considering that ~2.5 seconds startup time, for a Spring Boot application, is actually not too bad, other services take much longer.
Step #2 – The native image
Everyone wants to do Java “native compilation”. I guess the expectation is that native compilation makes everything go much faster. There are different tests by different people, comparing native compilation and JVM mode, and the outcomes vary a lot. I don’t think that “native images” are a silver bullet to performance issues, but still, we have been curious to give it a try and see what happens.
Native image with Quarkus
Enabling native image mode in Quarkus is trivial. You need to add a Maven profile, set a few properties and you have native image generation enabled. With setting a single property in the Maven POM file, you can also instruct the Quarkus plugin to perform the native compilation step in a container. With that, you don’t need to worry about the GraalVM installation on your local machine.
Native image generation can be tricky, we knew that. However, we didn’t expect this to be as complex as being “Step #2”. In a nutshell, creating a native image compiles your code to CPU instruction, rather than JVM bytecode. In order to do that, it traces the call graph, and it fails to do so when it comes to reflection in Java. GraalVM supports reflection, but you need to provide the information about types, classes, and methods that want to participate in the reflection system, from the outside. Luckily Quarkus provides tooling to generate this information during the build. Quarkus knows about constructs like de-serialization in Jackson and can generate the required information for GraalVM to compile this correctly.
However, the magic only works in areas that Quarkus is aware of. So we did run into some weird issues, strange behavior that was hard to track down. Things that worked in JVM mode all of a sudden were broken in native image mode. Not all the hints are in the documentation. And we also didn’t read (or understand) all of the hints that are there. It takes a bit of time to learn, and with a lot of help from some colleagues (many thanks to Georgios, Martin, and of course Dejan for all the support), we got it running.
What is the benefit?
After all the struggle, what did it give us?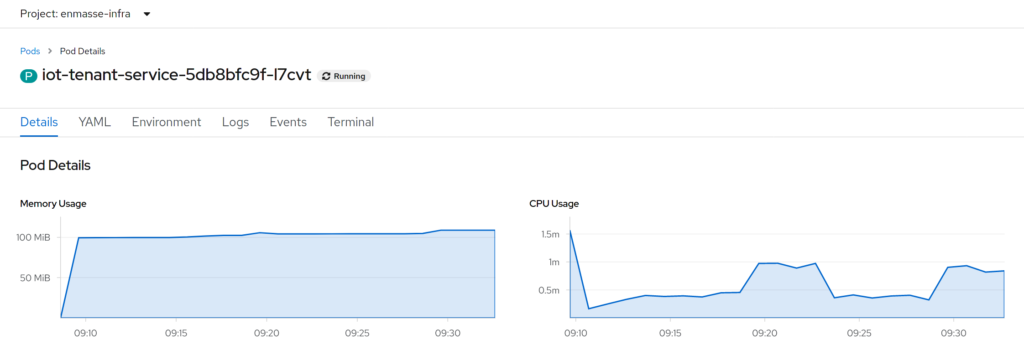
So, we are down another 50MiB of RAM. Starting from ~200MiB, down to ~100MiB. That is only half the RAM! Also, this time, we see a reduction in CPU load. While in JVM mode (both Quarkus and Spring Boot), the CPU load was around 2 millicores, now the CPU is always below that, even during application startup. Startup time is down from ~2.5 seconds with Spring Boot, to ~2 seconds with Quarkus in JVM mode, to ~0.4 seconds for Quarkus in native image mode. Definitely an improvement, but still, neither of those times is really bad.
Pros and cons of Quarkus
Switching to Quarkus was no problem at all. We found a few areas in the Hono configuration classes to improve. But in the end, we can keep the original Spring Boot setup and have Quarkus at the same time. Possibly other Microprofile compatible frameworks as well, though we didn’t test that. Everything worked as before, just using less memory. And except for the configuration classes, we could pretty much keep the whole application as it was.
Native image generation was more complex than expected. However, we also saw some real benefits. And while we didn’t do any performance tests on that, here is a thought: if the service has the same performance as before, the fact that it requires only half the of memory, and half the CPU cycles, this allows us to run twice the amount of instances now. Doubling throughput, as we can scale horizontally. I am really looking forward to another scale test since we did do all other kinds of optimizations as well.
You should also consider that the process of building a native image takes quite an amount of time. For this, rather simple service, it takes around 3 minutes on an above-than-average machine, just to build the native image. I did notice some decent improvement when trying out GraalVM 20.0 over 19.3, so I would expect some more improvements on the toolchain over time. Things like hot code replacement while debugging, are things that are not possible with the native image profile though. It is a different workflow, and that may take a bit to adapt. However, you don’t need to commit to either way. You can still have both at the same time. You can work with JVM mode and the Quarkus development mode, and then enable the native image profile, whenever you are ready.
Taking a look at the size of the container images, I noticed that the native image isn’t smaller (~85 MiB), compared to the uber-JAR file (~45 MiB). Then again, our “java base” image alone is around ~435 MiB. And it only adds the JVM on top of the Fedora minimal image. As you don’t need the JVM when you have the native image, you can go directly with the Fedora minimal image, which is around ~165 MiB, and end up with a much smaller overall image.
Conclusion
Switching our existing Java project to Quarkus wasn’t a big deal. It required some changes, yes. But those changes also mean, using some more open APIs, governed by the Eclipse Foundation’s development process, compared to using Spring Boot specific APIs. And while you can still use Spring Boot, changing the configuration to Eclipse MicroProfile opens up other possibilities as well. Not only Quarkus.
Just by taking a quick look at the numbers, comparing the figures from Spring Boot to Quarkus with native image compilation: RAM consumption was down to 50% of the original, CPU usage also was down to at least 50% of original usage, and the container image shrank to ~50% of the original size. And as mentioned in the beginning, we have been using Vert.x for all the core processing. Users that make use of the other Spring components should see more considerable improvement.
Going forward, I hope we can bring the changes we made to the next versions of EnMasse and Eclipse Hono. There is a real benefit here, and it provides you with some awesome additional choices. And in case you don’t like to choose, the EnMasse operator has some reasonable defaults for you 😉
Also see
This work is based on the work of others. Many thanks to:
GitHub branch: ctron/enmasse#feature/quarkus_tenant_1